Digital Dispatches
March 4, 2025

ISD UK, ISD-US
Emerging Technologies, Recommender Systems and Algorithms, Terrorism and Extremism
Hidden hate: How Amharic is being used to evade hate speech detection on TikTok
ISD has observed the use of Amharic, a Semitic language spoken by millions in Ethiopia and among diaspora communities, increasingly being used on TikTok to spread hate speech and bypass moderation filters. By combining Amharic text with hateful text written in European languages, bad actors can prevent the automatic removal of posts which appear to violate TikTok’s Community Guidelines and/or the European Union’s Digital Services Act (DSA). The use of Amharic has been observed in two main forms: ‘coded’, where hate speech is written in Ge’ez script (see Figure 3), and ‘bypass’, where hate speech is written in a European language alongside the Ge’ez script. Both methods have been observed to be successful in avoiding moderation even after reporting.
Key findings
- Hate speech in a range of European languages is being masked using Amharic, a strategy identified in 134 comments on TikTok. This content appears to contravene the EU’s DSA, TikTok’s community guidelines, or both.
- Previous studies on computing and natural language processing have pointed to the challenge of policing hate speech by native Amharic speakers, reflecting technical challenges and inequalities in the resources platforms allocate to different languages.
- Bad actors used Amharic to mask hate speech in two ways – coded and bypass: the first, codes hate speech by translating it directly into Amharic (Ge’ez script), while the second bypasses by placing Amharic text alongside hate speech written in European languages.
- Of 16 comments reported to TikTok, the platform removed or limited the visibility of only 5.[1] This suggests that TikTok’s systems are failing to recognise hate speech, even when written in English and manually reported, if it is appears alongside Amharic language text.
- ISD found evidence of similar tactics in other languages with limited moderation, suggesting that bad actors are innovating and exploiting this vulnerability.
Methodology
Amharic, one of the most widely spoken languages in Ethiopia, is a low-resource language that uses the Ge’ez script. A low-resource language is a language with less online data available to train natural language processing systems, which platforms often use to automatically moderate content. Existing research on Amharic content on social media often highlights the difficulties of detecting hate speech in Amharic. However, these previous studies were focused on Amharic content produced by native speakers in a regional context, where the posts were all in Amharic.
While conducting manual collection of hate speech in European countries, researchers unexpectedly found messages including Amharic text in TikTok comment sections that were otherwise primarily in European languages. ISD found 134 comments containing hateful or insulting language that featured Amharic text either directly (coded) or in combination with a European language (bypass). These comments were posted between May and August 2024 and featured 10 European languages (outlined in the chart below).
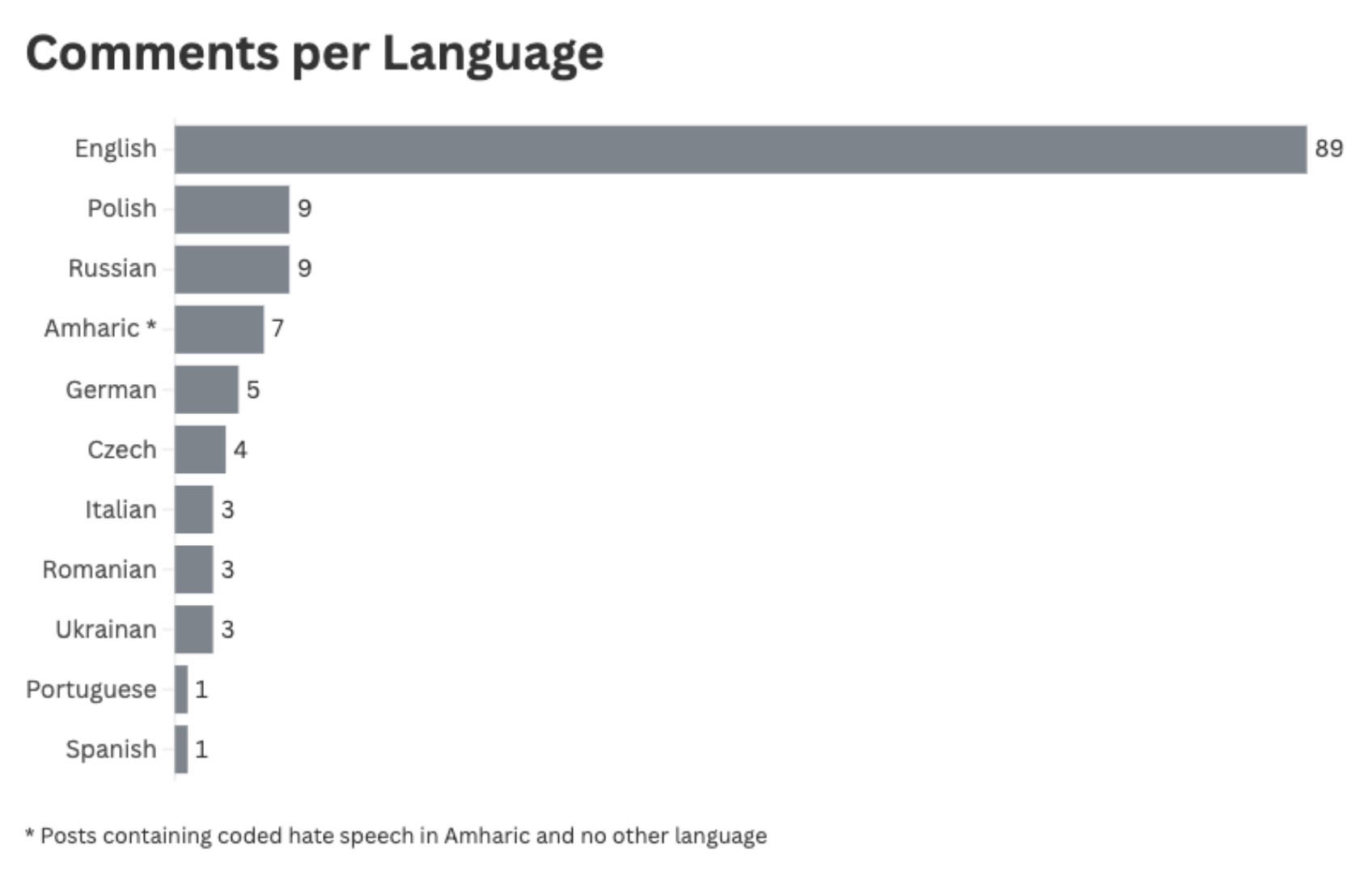
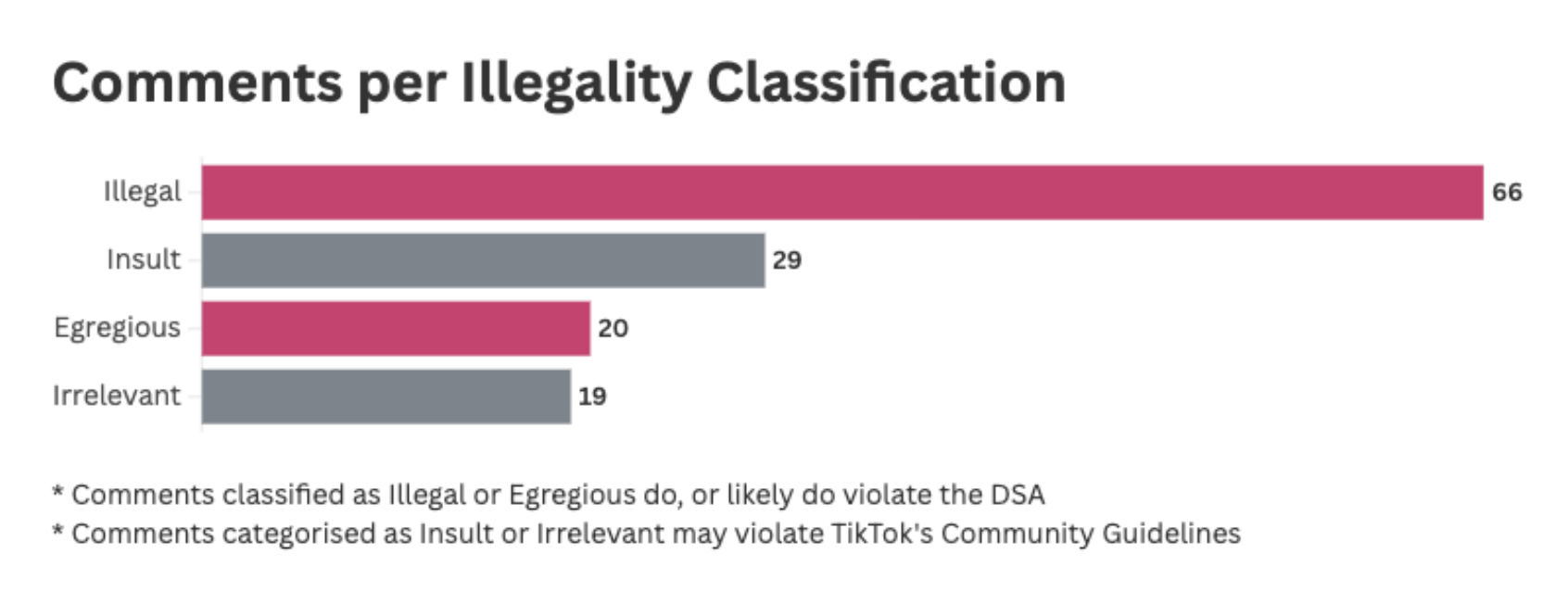
Comments collected by ISD varied in their severity and were categorised as follows:
- Illegal: Comments which contain explicit calls to violence against a protected group.
- Egregious: Comments which contain slurs.
- Insult: Comments which contain swear words or insults.
- Irrelevant: Comments used to test the bypass method, teach others or that contain discussions of sensitive topics.
Comments categorised as illegal or egregious hate speech were more likely to meet definitions for hate speech as defined by the DSA, which requires a clear incitement to violence against a target group of a protected category. Comments categorised as an insult or irrelevant are more likely to only violate TikTok’s community guidelines. Most irrelevant comments were found in the context of discussions around sensitive topics, such as religious conflict. This suggests they were used as a precaution against moderation.
All 134 comments were found in the comments sections of posts (in European languages) related to illegal or controversial topics, such as glorification of far-right terrorism, Holocaust denial, or discussion of ethnic cleansing and religious conflict. All 134 comments were either illegal, egregious, insulting, or used in discussing sensitive topics. While this appears to currently be a trend that is limited to a small number of users, it is important to note that this is exploratory research and further work is needed.
Findings
Of the 134 comments, ISD found that 116 used Amharic to ‘bypass’ moderation. This typically involved copying a standard text in Amharic and pasting it alongside hate speech written in a European language. The most common versions of these copy-pasted texts translate to messages that either indicate the intent to teach other users how to evade moderation or contain an appeal to the platform not to remove their comment.

Hate speech directly translated into Amharic was a less common tactic, appearing in 18 of 134 comments. However, it represented a higher percentage of explicit hate speech: 17 out of 18 translated comments contained clear incitements to violence and the remaining comment contained a racial slur.
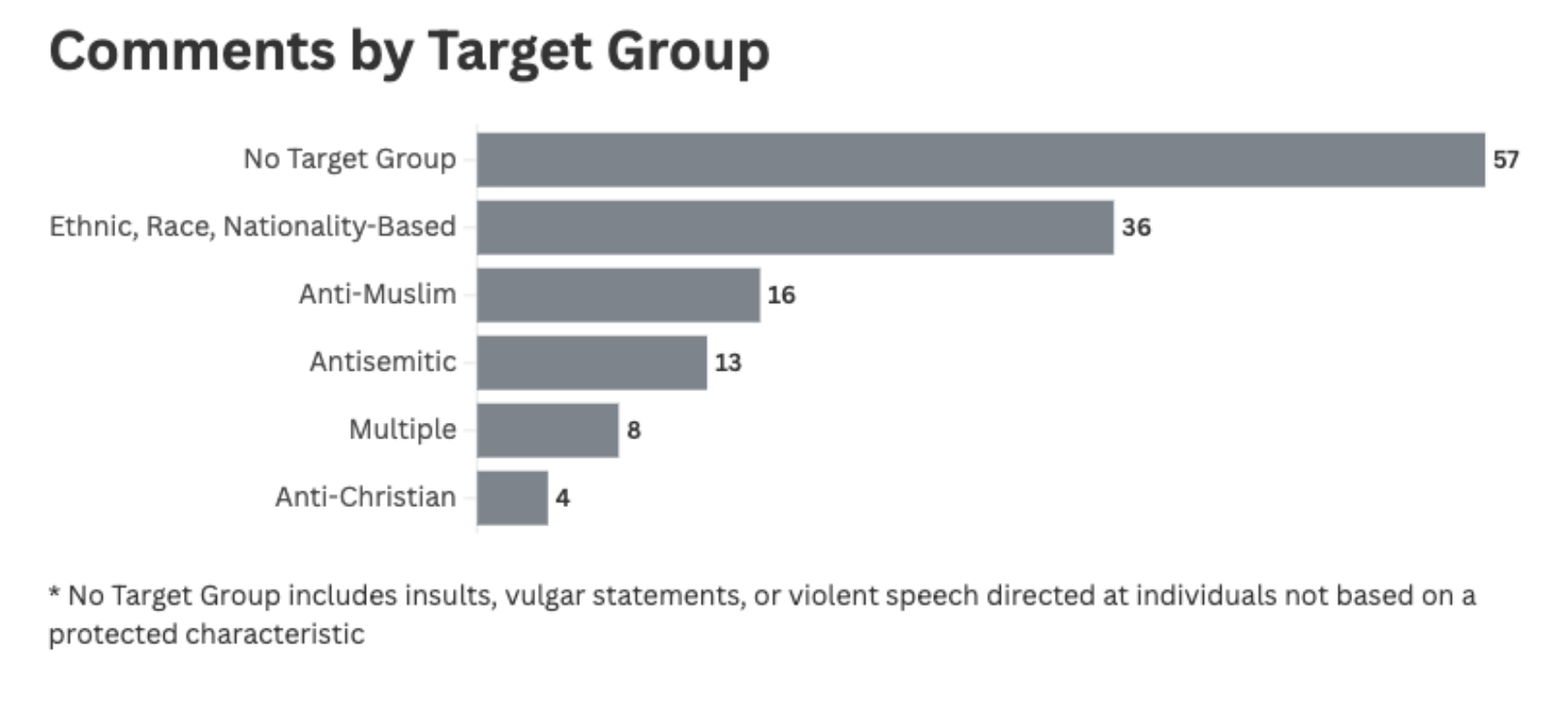
The technique was most often used to hide hate speech targeting ethnic, race and nationality-based groups, which are most often targets of anti-immigrant sentiment. The second most common targets were religious groups, primarily Muslims, Jews and Christians. The ‘multiple’ category was applied to comments which directed hate at one or more protected groups. ‘No target group’ was applied to comments which targeted individuals, especially comments that included insulting language.
These target groups align with the predominant victims of discourse surrounding the glorification of far-right terrorism, Holocaust denial and ethnic cleansing, where these comments were found. Further research is required to identify the exact groups that are using this method, but this exploratory research suggests that topics often discussed or promoted by neo-Nazi and white nationalist groups appear to be the initial users and promoters of this method.
Moderation
ISD reported a sample of 16 comments that were classified as illegal or egregious. These posts were chosen on the basis of representing both high and low resource languages and the highest degree of illegality. Only 11 of the reported comments received responses, with TikTok indicating it would act on only 5. Of the 6 remaining posts that TikTok said would not be removed, 5 contained explicit language calling for genocide against a protected group. All but one of these posts remain available online. 4 of these 6 were in English, while the other two were in Polish and Czech.
TikTok’s decision to not remove these posts highlights a serious flaw in how the platform reviews reports, compounding its failure to moderate this content at the time of posting. This also suggests that TikTok’s review process after DSA reporting may be automated, as a manual review of explicit calls for genocide would likely have resulted in moderation.[2] Despite the small sample size, TikTok’s automatic moderation system presented significant issues in recognising illegal hate speech in English when written alongside Amharic.
Spread and Scale
The use of Amharic as a tool to promote hate speech in other languages has been primarily observed on TikTok. However, some instances were also found on X. The method appears to spread organically between users, with individuals teaching each other in comments sections. Three Reddit posts discussing the phenomenon were found, posted around July 2024 when this was first observed by ISD.
The use of other languages and non-Latin alphabets to ‘bypass’ moderation, including Punjabi, Nepali, Konkani, and Tigrinya, has also been observed by ISD. Although the sample size of these languages is limited, it nevertheless suggests that users are picking up on the vulnerability of low-resource languages and alphabets and exploiting it with the language of their choice.
Conclusion
The ‘coded’ and ‘bypass’ methods effectively evade the automated moderation systems of high-resource languages by exploiting low-resource languages and non-Roman alphabets to confuse language filters and avoid moderation. This is a dangerous vulnerability that can spread and be exploited by bad actors and exposes the limitations of relying entirely on automated moderation systems, especially for reviewing reports made through DSA legal forms. The failure to identify and moderate coded language also allows bad actors to easily rebuild networks and account followings, even after their accounts have been suspended from the platform. TikTok should first reevaluate its moderation systems so that ‘bypass’-type uses of non-Roman alphabets do not allow hate speech in high-resource languages to escape moderation at both the initial time of posting and after being reported. TikTok should also focus its computational and natural language processing capabilities to focus on non-Roman alphabets and low-resource languages that can be exploited for this purpose by bad actors.
End notes
[1] The sample of 16 was chosen for reporting based on the highest degree of illegality and representation of both low and high-resource languages.
[2] Platforms are required by the DSA to provide specific legal forms for reporting content which is illegal in the European Union. The comments in this sample were reported through TikTok’s DSA-specific legal form instead of through regular internal reporting options.